Equivariant NQS: GCNN for Spin models#
About this tutorial: This tutorial demonstrates using Group Convolutional Neural Networks (G-CNNs), which are neural networks that are explicitly designed to respect symmetries through their architecture. This is in contrast to the approach shown in the Symmetries and VMC tutorial, which uses symmetry projection to enforce symmetries on arbitrary neural networks that don’t inherently respect those symmetries.
The goal of this tutorial is to learn about group convolutional neural networks (G-CNNs), a useful tool for simulating lattices with high symmetry. The G-CNN is a generalization to the convolutional neural network (CNN) to non-abelian symmetry groups (groups that contain at least one pair of non-commuting elements). G-CNNs are a natural fit for lattices that have both point group and translational symmetries, as rotations, reflections and translations don’t commute with one-another. G-CNN can be used to study both the ground-state and excited-states.
In this tutorial we will learn the ground state of the antiferromagnetic Heisenberg model on the honeycomb lattice. The Heisenberg Hamiltonian is defined as follows:
where \(\vec{\sigma}_{i}\) are Pauli matrices and \(<>\) denotes nearest neighbor interactions.
For this tutorial, many of the calculations will be much faster on a GPU. If you don’t have access to a GPU, you can open a Google Colab notebook, and set runtime type to GPU. To launch this notebook on Colab simply press the rocket button on the top bar.
This tutorial wil be split into two parts:
First I’ll provide a brief introduction to G-CNNs and describe what advantages they bring.
Second, we’ll use NetKet to find the ground state of the antiferromagnetic Heisenberg model on the honeycomb lattice. First we will simulate a lattice with \(N=18\) sites in order to compare with exact diagonalization. Then we will simulate a lattice with \(N=72\) sites.
G-CNNs are generalizations of CNNs to non-abelian groups#
The convolutional neural network (CNN) has revolutionized the field of computer vision. The CNN enforces translational invariance, which means that feeding a CNN translated copies of an image will produce the exact same output. This is important for recognizing objects, which may located differently in different images.
The hidden layers of a CNN contain a group of \({\bf features}\), corresponding to translations of the image, where each feature is represented by a vector. At each layer, the CNN integrates over these features to produce a different set of features over the translation group:
As you can see, the index of the filter W is based on the displacement between the input feature {x’,y’} and the output feature {x, y}. This is known as an equivariant operation, as displacements in the input are propagated as displacements in the output (equivariance is actually bit more general, we’ll get to that in a moment). In the last layer, the CNN averages over these different features, forcing the output to be invariant to the input.
To generalize the CNN to the G-CNN, lets abstract away from the specifics of the convolution. Instead of indexing the features with translations, we will use elements from a general symmetry group which may contain non-commuting operations. In this case we must define a particular order of operations. For example, we could define an operation in the \(p6m\) space group, as a translation, followed by a rotation and a reflection about the origin. Non-abelian groups still maintain associativity and a closed algebra. This is easy to see with lattice symmetry groups. If two successive symmetry operations leave the lattice unchanged, applying both must also leave the lattice unchanged and therefore be symmetry operation in the group.
For G-convolutions, the building blocks of the G-CNN, this algebra is all we need. The G-convolution also indexes the filters by looking at the “difference” between group elements, however this time there is an orientation to it. The G-convolution is defined as follows:
The filters are indexed by \(g^{-1} h\), which describes the mapping from \(g \rightarrow h\) but not vice-versa. This causes the output to be an \({\bf involution}\) of the input, meaning that the group elements are mapped to their respective inverses.
G-convolutions are the most expressive linear transformation over a particular symmetry group. Therefore, if you want to define a linear-based model with a particular symmetry, G-CNNs maximize the number of parameters you can fit into a given memory profile. G-CNNs can be mapped down to other symmetry-averaged multi-layer linear models by masking filters (setting them to zero). On the Honeycomb lattice, the G-CNN (approximately) has a factor of 12 more parameters than a CNN averaged over \(d_6\) and a factor of \(12 N\) more parameters than a feedforward neural network averaged over \(p6m\) (where N is the number of sites) under an identical memory constraint.
If you’d like to learn more about G-CNNs, check out the original paper by Cohen \({\it et \ al.}\) or this paper by Roth \({\it et \ al.}\) that applies G-CNNs to quantum many-body systems.
%pip install --quiet netket
WARNING: You are using pip version 22.0.2; however, version 22.0.3 is available.
You should consider upgrading via the '/home/filippovicentini/Documents/pythonenvs/utils-jupuyterlab/bin/python -m pip install --upgrade pip' command.
Note: you may need to restart the kernel to use updated packages.
import netket as nk
# Import Json, this will be needed to examine log files
import json
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
Defining the Hamiltonian#
We begin by defining the Hamiltonian as a list of lattice points. NetKet will automatically convert these points into a graph with nearest neighbor connections. The honeycomb lattice is a triangular lattice with two sites per unit cell.
# Basis Vectors that define the positioning of the unit cell
basis_vectors = [[0, 1], [np.sqrt(3) / 2, -1 / 2]]
# Locations of atoms within the unit cell
atom_positions = [[0, 0], [np.sqrt(3) / 6, 1 / 2]]
# Number of unit cells in each direction
dimensions = [3, 3]
# Define the graph
graph = nk.graph.Lattice(
basis_vectors=basis_vectors, atoms_coord=atom_positions, extent=dimensions
)
Lets check to see if our graph looks as expected. Since we have two sites per unit cell, we should have \(3 \times 3 \times 2 = 18\) sites. The coordination number of a hexagonal lattice is 3, so we should have \(\frac{18 \times 3}{2} = 27\) edges. Finally we have p6m symmetry, which should give ue \(3 \times 3 \times 12 = 108\) symmetry operations.
# Use Netket to find symmetries of the graph
symmetries = graph.automorphisms()
# Check that graph info is correct
print(graph.n_nodes)
print(graph.n_edges)
print(len(symmetries))
18
27
216
Oops! It looks like we have twice as many symmetries elements as we thought. Luckily for us, the ground state is still symmetric with respect to this extra symmetry that is unique to the \(3 \times 3\) lattice. We use this graph to define our Hilbert space and Hamiltonian:
# Define the Hilbert space
hi = nk.hilbert.Spin(s=1 / 2, N=graph.n_nodes, total_sz=0)
# Define the Hamiltonian
ha = nk.operator.Heisenberg(hilbert=hi, graph=graph, sign_rule=True)
Since the Hexagonal lattice is bipartite, we know the phases obey a Marshall-Peierls sign rule. Therefore, we can use a real valued NN and just learn the amplitudes of the wavefunction.
For models with a more complicated phase structure, its often better to learn the phases in an equal-amplitude configuration before training the amplitudes as detailed in this paper. This can be implemented by first optimizing the weights on a modified model that sets \(Re[log(\psi)] = 0\)
We also optimize over states with total \(S_z\) of zero since we know the ground state has spin 0.
Defining the GCNN#
We can define a GCNN with an arbitrary number of layers and specify the feature dimension of each layer accordingly:
# Feature dimensions of hidden layers, from first to last
feature_dims = (8, 8, 8, 8)
# Number of layers
num_layers = 4
# Define the GCNN
ma = nk.models.GCNN(symmetries=symmetries, layers=num_layers, features=feature_dims)
This a G-CNN with four layers, where each hidden layer contains a feature vector of length 8 for each element in p6m. This means that each hidden state has \(8 \times 192 = 768\) nodes. This is a huge model! But since we’re not symmetry-averaging, we only need to compute one wavefunction for each \({\bf \sigma}\).
Feel free to try different shaped models. By default, the GCNN weights are initialized with variance scaling, which ensures that the activations will be unit-normal throughout the model at the start of training. Additionally, GCNN defaults to a SELU non-linearity, which moves the activations in the direction of unit-normal, even when they start to deviate. These features ensure that our model will behave well, even when we stack a large number of layers.
Variational Monte Carlo#
In order to perform VMC we need to define a sampler and an optimizer. We sample using Metropolis-Hastings, which uses the exchange rule to propose new states. The exchange rule swaps the spin of two neighbouring sites, keeping the magnetization fixed (in this case, 0). We optimize using stochastic reconfiguration, which uses curvature information to find the best direction of descent.
# Metropolis-Hastings with two spins flipped that are at most second nearest neighbors
sa = nk.sampler.MetropolisExchange(hilbert=hi, graph=graph, d_max=2)
# Stochastic reconfiguration
op = nk.optimizer.Sgd(learning_rate=1e-2)
sr = nk.optimizer.SR(diag_shift=0.01)
# Define a variational state so we can keep the parameters if we like
vstate = nk.variational.MCState(sampler=sa, model=ma, n_samples=100)
# Define a driver that performs VMC
gs = nk.driver.VMC(ha, op, sr=sr, variational_state=vstate)
Lets start by running for 100 iterations. This took about 15 seconds per iteration on my CPU and about 1 second per iteration on the Tesla P100 GPU (If you’re using the free version of Colab you may get a Tesla K80 which is slightly slower). GPUs are fast! As you’ll see later, the speedup is even more pronounced on larger lattices.
# Run the optimization
gs.run(n_iter=100, out="out")
100%|██████████| 100/100 [01:06<00:00, 1.51it/s, Energy=-40.471 ± 0.046 [σ²=0.238, R̂=0.9744]]
(<netket.logging.json_log.JsonLog at 0x7fea898371d0>,)
This should get us under 0.1% error. Lets see how the energy evolves as we train.
# Get data from log and
energy = []
data = json.load(open("out.log"))
for en in data["Energy"]["Mean"]:
energy.append(en)
# plot the energy during the optimization
plt.xlabel("Number of Iterations")
plt.ylabel("Energy")
plt.plot(energy)
[<matplotlib.lines.Line2D at 0x7fe6a2426510>]
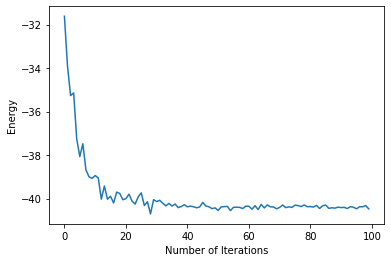
Looks like the first 40 iterations did most of the work! In order to get a more precise estimate, we can run 100 more iterations with a larger batch size. This will take about 15 minutes on the GPU (If you’re using a CPU, I suggest you skip this section). We access the batch size via the variational state.
# Change batch size
vstate.n_samples = 1000
# Driver uses new batch size
gs = nk.driver.VMC(ha, op, sr=sr, variational_state=vstate)
# Run for 100 more iterations
gs.run(n_iter=100, out="out")
100%|██████████| 100/100 [10:43<00:00, 6.43s/it, Energy=-40.3884 ± 0.0045 [σ²=0.0207, R̂=1.0033]]
(<netket.logging.json_log.JsonLog at 0x7fe6a31f2d90>,)
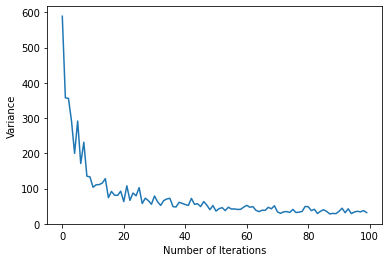
You will notice that the variance continues to get even smaller, giving evidence that we are nearing an eigenstate.
Checking with ED#
It seems likely that our ground state is correct, as we approached an eigenstate with low energy, but lets be safe and check our work. We can do Lanczos diagonalization for small lattices in NetKet.
# Exact Diagonalization
E_gs = nk.exact.lanczos_ed(ha, compute_eigenvectors=False)
Lets compare the VMC energy with the ED energy, by taking average energy over the last \(20\) iterations
# Get data from larger batch size
energy = []
data = json.load(open("out.log"))
for en in data["Energy"]["Mean"]:
energy.append(en)
vmc_energy_18sites = np.mean(np.asarray(energy)[-20:]) / 18
ED_energy_18sites = E_gs[0] / 18
print(vmc_energy_18sites)
print(ED_energy_18sites)
print((ED_energy_18sites - vmc_energy_18sites) / ED_energy_18sites)
-2.2437762156893766
-2.243814630334411
1.7120240021148795e-05
Looks like our model did a good job! If you just trained for the first 100 iterations the error should be less than \(10^{-4}\) and if you trained with the larger batch size, the error should be close to \(10^{-5}\)
Simulating A Larger Lattice#
Lets see how the GCNN does on a larger lattice that cannot be simulated with exact diagonalization. We’ll do a \(6 \times 6\) lattice which has \(72\) sites. We need to redefine a few things:
# Redefine bigger graph
dimensions = [6, 6]
# Define the graph
graph = nk.graph.Lattice(
basis_vectors=basis_vectors, atoms_coord=atom_positions, extent=dimensions
)
# Redefine the Hilbert/Hamiltonian for larger lattice space
hi = nk.hilbert.Spin(s=1 / 2, N=graph.n_nodes, total_sz=0)
ha = nk.operator.Heisenberg(hilbert=hi, graph=graph, sign_rule=True)
# Compute the symmetries for the bigger graph
symmetries = graph.automorphisms()
print(len(symmetries))
# Redefine everything on bigger graph
ma = nk.models.GCNN(symmetries=symmetries, layers=num_layers, features=feature_dims)
sa = nk.sampler.MetropolisExchange(hilbert=hi, graph=graph, d_max=2)
vstate = nk.variational.MCState(
sampler=sa, model=ma, n_samples=100, n_discard_per_chain=100
)
gs = nk.driver.VMC(ha, op, sr=sr, variational_state=vstate)
432
Looks like we have no extra symmetries this time, since \(6 \times 6 \times 12 = 432\). Let’s run this model for 100 iterations. You will see that we quickly get close to the ground state. This takes 15 minutes on a P100 GPU
energy = []
variance = []
gs.run(n_iter=100, out="out")
data = json.load(open("out.log"))
for en in data["Energy"]["Mean"]:
energy.append(en)
for var in data["Energy"]["Variance"]:
variance.append(var)
100%|██████████| 100/100 [14:53<00:00, 8.93s/it, Energy=-155.43 ± 0.53 [σ²=31.79, R̂=0.9946]]
We can plot the energy and variance to see if we’re approaching an eigenstate
plt.xlabel("Number of Iterations")
plt.ylabel("Energy")
plt.plot(energy)
[<matplotlib.lines.Line2D at 0x7f20e9c2b190>]
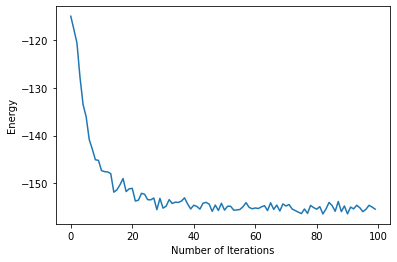
plt.xlabel("Number of Iterations")
plt.ylabel("Variance")
plt.plot(variance)
[<matplotlib.lines.Line2D at 0x7f20e9702e90>]
It seems we are near an eigenstate. We can do a back-of-the-envelope calculation to see if this is a realistic ground state energy
print(ED_energy_18sites)
print(energy[-1] / graph.n_nodes)
-2.243814630334411
-2.158805247393738
The energy for the bigger lattice is slightly less negative (as is typical for Heisenberg models with PBC) but they are pretty similar. It’s clear we are approaching the ground state
We will benchmark how well our model is performing by tracking the relationship between the mean and variance of the energy over 400 more iterations. Then we will extrapolate this relationship to estimate the true ground state energy. This can tell us how our error evolves over time.
intervals = 20
en_estimates = []
var_estimates = []
for interval in range(intervals):
# run for 100 iterations
gs.run(n_iter=20, out="out")
# load data from iterations
data = json.load(open("out.log"))
# append energies and variances to data
for en in data["Energy"]["Mean"]:
energy.append(en)
for var in data["Energy"]["Variance"]:
variance.append(var)
en_est = np.mean(energy[-20:])
var_est = np.mean(variance[-20:])
en_estimates.append(en_est)
var_estimates.append(var_est)
print("\n")
print(en_est)
print(var_est)
-156.9362404126101
10.740704288189896
100%|██████████| 20/20 [02:56<00:00, 8.81s/it, Energy=-157.22 ± 0.32 [σ²=11.34, R̂=0.9780]]
Lets plot the energy vs. variance and draw a line of best fit
plt.xlabel("Variance")
plt.ylabel("Energy")
plt.scatter(var_estimates, en_estimates)
fit = np.polyfit(var_estimates, en_estimates, 2)
x = np.arange(100) * np.max(var_estimates) / 100
plt.plot(x, fit[2] + fit[1] * x + fit[0] * np.square(x))
[<matplotlib.lines.Line2D at 0x7f20e4704410>]
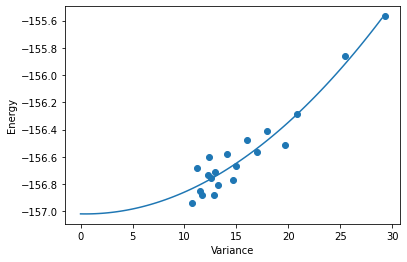
You can see that that the relationship between energy and variance is fairly well captured by a quadratic function. We can use this extrapolation to estimate the true ground state energy and the error in our wavefunction. Lets estimate the final energy of our Ansatz using our last 10,000 samples
final_en = np.mean(en_estimates[-5:])
extrapolated_est = fit[2]
print((extrapolated_est - final_en) / extrapolated_est)
0.0012942848437390558
If everything went well your error should be around .1%!
This concludes the tutorial. Only an hour ago we knew nothing about the Heisenberg model on a Hexagonal lattice. Now we have an accurate approximation of the ground state wavefunction!