Ground-State: Bosonic Matrix Model#
Enrico Rinaldi, July 13, 2022
In this tutorial we will use the open-source package NetKet to find the ground state (in a variational sense) of a quantum mechanical system of matrices. This system is referred to as a free bosonic matrix model and was studied in this PRX Quantum paper using quantum technologies (e.g. based on qutip and qiskit) and Lattice Monte Carlo methods.
Specifically, we will study the system defined by the Hamiltonian:
where $\(\hat{P}_I=\sum_{\alpha=1}^{N^2-1}\hat{P}_I^\alpha\tau_\alpha\)$
and
for a SU(N) gauge group with \(N^2-1\) generators \(\tau_\alpha\) (normalized such that \({\rm Tr}(\tau_\alpha \tau_\beta) = \delta_{\alpha\beta}\)). In the Hamiltonian, \(g^2\) is the coupling constant representing the strenght of the interaction between matrices \(X_I\). The physical states of this system are gauge singlets. We also set \(m^2=1\) so that the first two terms in the Hamiltonian represent a set of free harmonic oscillators with unit frequency.
0. Installing Netket#
Installing NetKet is relatively straightforward. For this tutorial, if you are running it locally on your machine, we recommend that you create a clean virtual environment (e.g. with conda) and install NetKet within (using pip):
conda create --name netket python pip ipython
conda activate netket
pip install --upgrade netket
If you are on Google Colab, uncomment and run the following cell to install the required packages.
#!pip install --upgrade netket
You can check that the installation was succesfull doing
import netket as nk
You should also check that your version of netket is at least 3.0
print(f"NetKet version: {nk.__version__}")
NetKet version: 3.4.3.dev29+gfe47c195
!python -m netket.tools.info
====================================================
== NetKet Diagnostic Information ==
====================================================
NetKet version : 3.4.3.dev29+gfe47c195
# Python
- implementation : CPython
- version : 3.10.5
- distribution : Clang 13.0.1
- path : /Users/enrythebest/miniforge3/envs/netket-mpi/bin/python
# Host information
- System : macOS-12.4-arm64-arm-64bit
- Architecture : arm64
Traceback (most recent call last):
File "/Users/enrythebest/miniforge3/envs/netket-mpi/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/Users/enrythebest/miniforge3/envs/netket-mpi/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/Users/enrythebest/miniforge3/envs/netket-mpi/lib/python3.10/site-packages/netket/tools/info.py", line 167, in <module>
info()
File "/Users/enrythebest/miniforge3/envs/netket-mpi/lib/python3.10/site-packages/netket/tools/info.py", line 81, in info
platform_info = cpu_info()
File "/Users/enrythebest/miniforge3/envs/netket-mpi/lib/python3.10/site-packages/netket/tools/_cpu_info.py", line 41, in cpu_info
return get_sysctl_cpu()
File "/Users/enrythebest/miniforge3/envs/netket-mpi/lib/python3.10/site-packages/netket/tools/_cpu_info.py", line 78, in get_sysctl_cpu
flags = [flag.lower() for flag in info["features"].split()]
KeyError: 'features'
import numpy as np
import matplotlib.pyplot as plt
1. Defining The Hamiltonian#
The first step in our journey consists in defining the Hamiltonian we are interested in. For this purpose, we first need to define the kind of degrees of freedom we are dealing with (i.e. if we have spins, bosons, fermions etc). This is done by specifying the Hilbert space of the problem.
For our problem we focus on the gauge group SU(2), which will determine the total number of bosons to be \(N^2-1 = 3\) for each matrix (\(\alpha, \beta \in \{ 1, 2, 3\}\)). We will focus on 2 matrices \(I, J \in \{ 1, 2 \}\), for a total of 6 bosonic degrees of freedom \(\hat{X}_{I,\alpha}\).
1.1 The Hilbert space#
For each bosonic degree of freedom we work in the basis of the Fock space, truncated up to a finite excitation level (cutoff) represented by \(\Lambda\).
Lambda = 4 # cutoff of each bosonic Fock space
N = 6 # number of bosons
hi = nk.hilbert.Fock(
n_max=Lambda - 1, N=N
) # n_max -> Maximum occupation for a site (inclusive)
Test if the space is constructed as we expected. We want each of the \(N\) bosons to have up to \(\Lambda\) excitations: the total Hilbert space is the tensor product of \(N\) individual Fock spaces of dimension \(\Lambda\) for a total size of \(\Lambda^N = 4^6 = 4096\).
# The size of the hilbert space on every site (we have 4 levels on 6 sites).
hi.shape
(4, 4, 4, 4, 4, 4)
# The total number number of degrees of freedom (6 bosons).
hi.size
6
# The total dimension of the many-body Hilbert space (4^6 = 4096)
hi.n_states
4096
assert Lambda**N == hi.n_states
We have checked that all the dimensions correspond to our expectations. We can think of this as the Hilbert state of a many-body system with \(N\) bosonic sites, each with excitations up to level \(\Lambda\) (inclusive, starting from 0 to \(\Lambda-1\)). In other words, it is a collection of harmonic oscillators in the \(\mid n \rangle\) basis.
1.2 The free Hamiltonian#
We now need to specify the Hamiltonian.
We will use some predefined operators for bosons, such as the create and destroy operators for each boson in the Hilber state (see the API documentation here).
In this specifc case, \(\hat{a}^\dagger_I\) for each boson \(I\) (we can regard this index as a site index in NetKet).
from netket.operator.boson import create, destroy
We now start by defining the free part of the Hamiltonian, which is just a collection of harmonic oscillators (for this part we could also use the number operator which is pre-defined in NetKet)
# we loop over all "sites" -> loop over N bosons
H_free = sum([0.5 + create(hi, i) @ destroy(hi, i) for i in range(N)])
NetKet automatically recognizes products of local operators as tensor products and the addition of scalars as if they were multiplied by the identity matrix in the tensor space. In this case, H_free acts on a 4096 dimensional space.
In general, when manipulating NetKet objects, you should always assume that you can safely operate on them like
you would in mathematical equations, therefore you can sum and multiply them with ease.
1.3 Exact Diagonalization#
Let us check this free Hamiltonian, whose eigenvectors are analytically known: the ground state has vacuum energy for \(N\) independent harmonic oscillators: \(0.5N = 0.5 \cdot 6 = 3\)
In NetKet we can convert our Hamiltonian operator into a sparse matrix of size \(\Lambda^N \times \Lambda^N \).
Or we can use the fact that NetKet provides a wrapper for eigsh in the form of a Lanczos exact solver which does not require to manipulate the Hamiltonian into a sparse matrix using .to_sparse.
eig_vals = nk.exact.lanczos_ed(
H_free, k=13, compute_eigenvectors=False
) # args to scipy.sparse.linalg.eighs like can be passed with scipy_args={'tol':1e-8}
print(f"Eigenvalues with exact lanczos (sparse): {eig_vals}")
Eigenvalues with exact lanczos (sparse): [3. 4. 4. 4. 4. 4. 4. 5. 5. 5. 5. 5. 5.]
Note: a full (dense) exact diagonalization can also be done for small systems using this exact solver
eig_vals = nk.exact.full_ed(H_free, compute_eigenvectors=False)
print(
f"Eigenvalues with exact diag (dense): {eig_vals}\nNumber of eigs: {eig_vals.shape[0]}"
)
Eigenvalues with exact diag (dense): [ 3. 4. 4. ... 20. 20. 21.]
Number of eigs: 4096
Clearly this is the correct energy for the ground state and we can also see the correct degeneracy (6) of the excited states due to the symmetry of the system (all sites are interchangeable)
1.4 The interaction Hamiltonian#
We can now continue building our full Hamiltonian by writing the interaction term.
It is convenient to write the interaction using the position operators built from the creation and annihilation bosonic operators
x_list = [(1 / np.sqrt(2)) * (create(hi, i) + destroy(hi, i)) for i in range(N)]
The interactoin terms can be written using the Levi-Civita completely antisymmetric tensor with 3 indices or by writing out all the terms by hand:
### Quartic Interaction for bosons
V_b = (
x_list[2] * x_list[2] * x_list[3] * x_list[3]
+ x_list[2] * x_list[2] * x_list[4] * x_list[4]
+ x_list[1] * x_list[1] * x_list[3] * x_list[3]
+ x_list[1] * x_list[1] * x_list[5] * x_list[5]
+ x_list[0] * x_list[0] * x_list[4] * x_list[4]
+ x_list[0] * x_list[0] * x_list[5] * x_list[5]
- 2 * x_list[0] * x_list[2] * x_list[3] * x_list[5]
- 2 * x_list[0] * x_list[1] * x_list[3] * x_list[4]
- 2 * x_list[1] * x_list[2] * x_list[4] * x_list[5]
)
And the full Hamiltonian with ‘t Hooft coupling \(\lambda = g^2 N_g\) (where \(N_g\) is the gauge group number of color, 2 in this example) is
g2N = 0.2 # 't Hooft coupling lambda
H = H_free + (g2N / 2) * V_b
2. Exact Diagonalization#
We can repeat for the full Hamiltonian at fixed gauge coupling \(g^2N_g\) the exact diagonalization procedure we have used on the free Hamiltonian.
When the gauge coupling constant is small, the difference of the energy of the ground state with the free case \(g=0\) will be small.
w = nk.exact.full_ed(H, compute_eigenvectors=False)
print(f"Eigenvalues with exact diag (dense): {w}\nNumber of eigs: {w.shape[0]}")
Eigenvalues with exact diag (dense): [ 3.13406307 4.21516634 4.21516634 ... 22.94954115 22.94954115
23.42952917]
Number of eigs: 4096
Or we can use the Lanczos solver and only approximately retrieve the lowest \(k\) eigenvalues (this is much much quicker)
eig_vals = nk.exact.lanczos_ed(
H, k=4, compute_eigenvectors=False, scipy_args={"tol": 1e-8}
)
print(f"Eigenvalues with exact lanczos (sparse): {eig_vals}")
Eigenvalues with exact lanczos (sparse): [3.13406307 4.21516634 4.21516634 4.21516634]
In this PRX Quantum paper, the author have shown how the ground state energy changes when the truncation level \(\Lambda\) of the Fock space is taken to infinity. The convergence to the infinite cutoff limit is exponentially fast and we can work with a small cutoff \(\Lambda=4\) in this example, to keep the computational requirements to a minimum.
3. Mean-Field Ansatz#
We now would like to find a variational approximation of the ground state of this Hamiltonian. As a first step, we can try to use a very simple mean field ansatz:
where the variational parameters are individual boson’s wave functions \(\Phi(X_i)\). This is probably a bad ansatz, but it will show how the variational Monte Carlo procedure works in NetKet
We can further write \( \Phi(X) = \sqrt{P(X)}e^{i \phi(X)}\). This is the same form used in the Deep Learning section of the same preprint cited above, where, instead of the Fock basis for the states, a coordinate basis was used.
In order to simplify the explanation of the Variational Monte Carlo method, we take the phase \(\phi=0\), and consider only the modulus of the wave function (the phase will be irrelevant for the ground state of this model).
For the normalized single-boson probability we will take a sigmoid form:
thus depending on the single, real-valued variational parameter \(\gamma\).
In NetKet one has to define a variational function approximating the logarithm of the wave-function amplitudes (or density-matrix values).
where \(\theta\) is a set of parameters.
In this case, the parameter of the model will be just one: \(\gamma\).
The Model can be defined using one of the several functional jax frameworks such as Jax/Stax, Flax or Haiku.
NetKet includes several pre-built models and layers built with Flax, so we will be using it for the rest of the notebook.
# always use jax.numpy for automatic differentiation of operations
import jax.numpy as jnp
# Flax is a framework to define models using jax
import flax.linen as nn
# A Flax model must be a class subclassing `nn.Module` (or later of nk.nn.Module)
class MF(nn.Module):
# The most compact way to define the model is this.
# The __call__(self, x) function should take as
# input a batch of states x.shape = (n_samples, L)
# and should return a vector of n_samples log-amplitudes
@nn.compact
def __call__(self, x):
# A tensor of variational parameters is defined by calling
# the method `self.param` where the arguments will be:
# - arbitrary name used to refer to this set of parameters
# - an initializer used to provide the initial values.
# - The shape of the tensor
# - The dtype of the tensor.
gam = self.param("gamma", nn.initializers.normal(), (1,), float)
# compute the probabilities
p = nn.log_sigmoid(gam * x)
# sum the output to return a single number (on a batch of input configurations)
return 0.5 * jnp.sum(p, axis=-1)
3.1 Variational State#
The model itself is only a set of instructions on how to initialise the parameters and how to compute the result.
To actually create a variational state with its parameters, the easiest way is to construct a Monte-Carlo-sampled Variational State.
To do this, we first need to define a sampler.
In netket.sampler several samplers are defined, each with its own peculiarities.
In the following example, we will be using a simple sampler that chooses the occupation number of each boson at random (uniform between 0 and \(\Lambda-1\)) one by one.
You can read more about how the sampler works by checking the documentation with ?nk.sampler.MetropolisLocal
# Create an instance of the model.
# Notice that this does not create the parameters.
mf_model = MF()
# Create the local sampler on the hilbert space
sampler = nk.sampler.MetropolisLocal(hi, n_chains=4)
# Construct the variational state using the model and the sampler above.
# n_samples specifies how many samples should be used to compute expectation
# values.
vstate = nk.vqs.MCState(sampler, mf_model, n_samples=2**9)
You can play around with the variational state: for example, you can compute expectation values yourself or inspect it’s parameters
# you can inspect the parameters which contain the single
# variational parameter `gamma`
vstate.parameters
FrozenDict({
gamma: DeviceArray([0.00979636], dtype=float64),
})
# Expectation value: notice that it also provides an error estimate. and the monte carlo chain properties, such as the Gelman-Rubin statistics across chains
vstate.expect(H)
12.95 ± 0.15 [σ²=8.93, R̂=1.0034]
The last cell was run with a randomly initialized parameter \(\gamma\) and for 512 samples (notice the metrics for the convergence of the Monte Carlo algorithm in square brackets).
4. Variational Monte Carlo#
We will now try to optimise \(\gamma\) in order to best approximate the ground state of the hamiltonian.
To do so, first I need to pick an iterative optimiser. The following is a choice that can be further optimized later on, depending on the learning curve for the specific ansatz and system.
We choose stochastic gradient descent with a learning rate of \(\eta = 0.05\).
Then, we must provide all the elements to the variational monte carlo driver, which takes case of setting up and running the whole optimisation.
For example, the driver can be run for a specific number of iterations. Each iteration will have to run the Monte Carlo sampling defined by the variational state nk.vqs.MCState.
optimizer = nk.optimizer.Sgd(learning_rate=0.05)
# build the optimisation driver
gs = nk.driver.VMC(H, optimizer, variational_state=vstate)
# Loggers that work together with optimisation drivers are defined in nk.logging.
# RuntimeLog keeps the metrics in memory, JsonLog stores them to a json file which can be read
# as a dict, TensorBoardLog can be used to log to TensorBoard.
log = nk.logging.RuntimeLog()
# One or more logger objects must be passed to the keyword argument `out`.
gs.run(n_iter=300, out=log)
# expectation value of the energy
mf_energy = vstate.expect(H)
# compare with the Lanczos exact diagonalization energy eigenvalue
error = abs((mf_energy.mean - eig_vals[0]) / eig_vals[0])
print(f"Optimized energy {mf_energy} \n and relative error: {error*100:.3f}%")
Optimized energy 3.258 ± 0.026 [σ²=0.118, R̂=1.0193]
and relative error: 3.956%
100%|██████████| 300/300 [00:04<00:00, 70.32it/s, Energy=3.228 ± 0.022 [σ²=0.087, R̂=1.0334]]
The optimization process outputs useful information such as the energy value, its standard error, its variance, and the Gelman-Rubin statistics \(\hat{R}\) (R-hat).
# we can also inspect the parameter:
print("Final optimized parameter: ", vstate.parameters["gamma"])
Final optimized parameter: [-5.28496854]
print(
f"Final optimized energy relative error (with mean-field ansatz): {error*100:.2f}%"
)
Final optimized energy relative error (with mean-field ansatz): 3.96%
Even a very rudimentary ansatz without interactions between the degrees of freedom is sufficient to reach a <10% error on the ground state energy with a single parameter to optimize.
We will see more complicated ansatzë below.
5. Jastrow Ansatz#
We have seen that the mean field ansatz yields about sub-10% error on the ground-state energy. Let’s now try to do better, using a more correlated ansatz.
We will now take a short-range Jastrow ansatz which is already inlcuded in NetKet as nk.models.Jastrow:
where \(W_{ij}\) is a symmetric matrix of learnable complex parameters (the kernel of the quadratic form).
# change the model: initialize weights with normal distributions
model = nk.models.Jastrow(kernel_init=nn.initializers.normal())
# we use the same MetropolicLocal sapmler as before. Now we sample for longer to get a more accurate result
vstate = nk.vqs.MCState(sampler, model, n_samples=2**10)
# look at the parameters
print(vstate.parameters)
FrozenDict({
kernel: DeviceArray([[ 0.01049682+0.01166978j, 0.00682185+0.00620781j,
0.00733915+0.01080751j, 0.00185571+0.00749652j,
-0.00214337+0.00025017j, -0.00318804-0.00774995j],
[-0.00512184-0.00538546j, 0.00184588-0.01090576j,
0.00651656-0.00574499j, 0.00724852-0.00697769j,
-0.01310518-0.00781628j, 0.0107602 +0.00490359j],
[-0.00207881-0.00916165j, 0.00700885+0.00145953j,
0.00113884-0.00484843j, -0.00317073-0.01036345j,
0.00207871+0.01423066j, 0.01065844+0.00981316j],
[ 0.00393085+0.01117876j, 0.00657261+0.00599069j,
-0.01086216-0.00661874j, 0.00182235+0.00389626j,
-0.00074458+0.0142108j , 0.00068885+0.00487905j],
[ 0.00323924+0.00014168j, -0.00236898+0.01239787j,
-0.00583072-0.00946589j, 0.00549118-0.0123498j ,
-0.00418706+0.00392197j, -0.00949517-0.00561518j],
[-0.00515065+0.00286905j, -0.00319454-0.00696432j,
-0.01778186-0.01000898j, -0.00727098+0.00334154j,
-0.01086984+0.00141303j, 0.0006615 -0.00233334j]], dtype=complex128),
})
We then optimize it, however this time we also introduce a stochastic reconfiguration (natural gradient) preconditioner:
optimizer = nk.optimizer.Sgd(learning_rate=0.05)
preconditioner = nk.optimizer.SR(diag_shift=0.1)
# driver for running the simulation
gs = nk.driver.VMC(
H, optimizer, variational_state=vstate, preconditioner=preconditioner
)
We now log the intermediate results of the optimization, so that we can visualize them at a later stage.
NetKet is very flexible and allows you to implement callbacks that can be used to report important information during the training process.
Here we add a callback to the VMC driver in order to save the acceptance rate of the sampling algorithm at each step of the optimization.
A callback takes the step of the training process, the logged_data dictionary and the driver as its arguments. The driver contains information about the acceptance rate in its state.sampler_state.
# define acceptance logger callback
def cb_acc(step, logged_data, driver):
logged_data["acceptance"] = float(driver.state.sampler_state.acceptance)
return True
# Loggers that work together with optimisation drivers are defined in nk.logging.
# RuntimeLog keeps the metrics in memory, JsonLog stores them to a json file which can be read
# as a dict, TensorBoardLog can be used to log to TensorBoard.
log = nk.logging.RuntimeLog()
# One or more logger objects must be passed to the keyword argument `out`. The callback is added with the `callback` argument
gs.run(n_iter=300, out=log, callback=cb_acc)
100%|██████████| 300/300 [00:06<00:00, 47.81it/s, Energy=3.1532-0.0000j ± 0.0024 [σ²=0.0035, R̂=1.0031]]
(RuntimeLog():
keys = ['Energy', 'acceptance'],)
print(f"Final optimized kernel parameters: {vstate.parameters['kernel']}\n")
jas_energy = vstate.expect(H)
error = abs((jas_energy.mean - eig_vals[0]) / eig_vals[0])
print(f"Optimized energy : {jas_energy}")
print(f"relative error : {error*100:.2f}%")
Final optimized kernel parameters: [[-1.70920011+1.71433180e-02j -0.05665743+5.16675585e-03j
-0.06777346+9.84367778e-03j -0.02855007-3.18257508e-04j
-0.11838393+2.13016722e-04j -0.12411947-9.27935996e-03j]
[-0.06860111-6.42651787e-03j -1.64852954-2.35979880e-02j
-0.06522334-8.32805942e-05j -0.09636936-6.51420533e-03j
-0.03033081-3.64966909e-03j -0.11377063+2.69651066e-03j]
[-0.07719142-1.01254905e-02j -0.06473105+7.12124247e-03j
-1.67554447-1.28902126e-02j -0.10571423-1.22707167e-02j
-0.10023615+1.11159834e-02j -0.01610114+1.94671388e-02j]
[-0.02647493+3.36398030e-03j -0.09704527+6.45416707e-03j
-0.11340566-8.52600511e-03j -1.66012998+1.25668208e-02j
-0.05191383+6.62303095e-03j -0.06245702+5.02777372e-03j]
[-0.11300132+1.04528231e-04j -0.01959461+1.65644798e-02j
-0.10814557-1.25805576e-02j -0.04567807-1.99375665e-02j
-1.65049581+1.04955161e-02j -0.06156012-8.77069255e-03j]
[-0.12608207+1.33964782e-03j -0.12772536-9.17140560e-03j
-0.04454144-3.54995508e-04j -0.07041686+3.49026603e-03j
-0.06293479-1.74248425e-03j -1.65837699-6.98319376e-03j]]
Optimized energy : 3.171-0.000j ± 0.011 [σ²=0.023, R̂=1.0233]
relative error : 1.19%
You can now see that this ansatz is almost one order of magnitude more accurate than the mean field!
In order to visualize what happened during the optimization, we can use the data that has been stored by the logger. There are several available loggers in NetKet, here we have just used a simple one that stores the intermediate results as values in a dictionary.
data_jastrow = log.data
print(data_jastrow)
{'Energy': History(
keys = ['Mean', 'Variance', 'Sigma', 'R_hat', 'TauCorr'],
iters = [0, 1, ... 298, 299] (300 steps),
), 'acceptance': History(
keys = ['value'],
iters = [0, 1, ... 298, 299] (300 steps),
)}
energy_history = data_jastrow["Energy"].Mean.real
energy_error_history = data_jastrow["Energy"].Sigma.real
These report several intermediate quantities, that can be easily plotted. For example we can plot the value of the energy (with its error bar) at each optimization step.
fig, ax = plt.subplots(figsize=(10, 5))
ax.errorbar(data_jastrow["Energy"].iters, energy_history, yerr=energy_error_history)
ax.axhline(
y=eig_vals[0],
xmin=0,
xmax=data_jastrow["Energy"].iters[-1],
linewidth=2,
color="k",
label="Exact",
)
ax.legend()
ax.set_xlabel("Iterations")
ax.set_ylabel("Energy (Re)")
Text(0, 0.5, 'Energy (Re)')
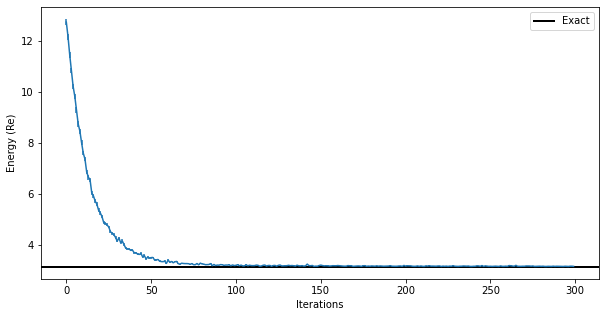
You can also look at the MCMC chain properties, like the Gelman-Rubin statistic (it should be very close to 1.00 for all chains to be equilibrated)
plt.plot(data_jastrow["Energy"].R_hat)
plt.ylabel("R_hat")
plt.xlabel("Iterations")
Text(0.5, 0, 'Iterations')
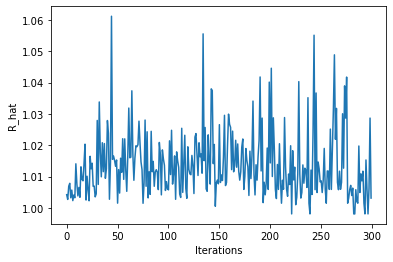
Some chains have R_hat larger than ones, which means they might not have converged within the \(2^{10}=1024\) samples that we had specified…
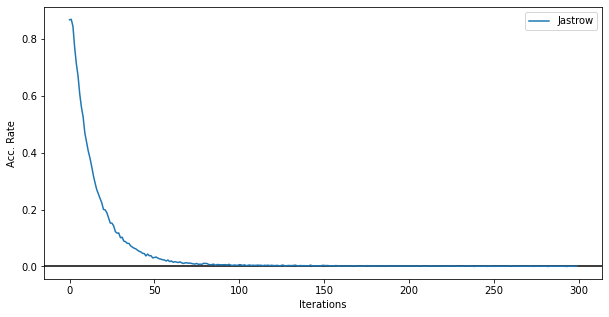
Moreover, we can look at the acceptance rate. In this figure below it is clear that the sampler is failing to explore the entirety of the Hilbert space and after 50 iterations the sampling starts failing and the local transition moves made by the sampler are not accepted by the Metropolis accept/reject step.
fig, ax = plt.subplots(figsize=(10, 5))
ax.errorbar(
data_jastrow["Energy"].iters, data_jastrow["acceptance"]["value"], label="Jastrow"
)
ax.axhline(0, c="k")
ax.legend()
ax.set_xlabel("Iterations")
ax.set_ylabel("Acc. Rate")
Text(0, 0.5, 'Acc. Rate')
5.1 Exact Sampling#
We can change the sampler to an exact sampler which does not suffer from autocorrelation effects and can sample from the exact Born distribution \(|\psi(x)|^2\) which is pre-computed on the entire Hilbert space. This is feasible only on small Hilbert spaces, like the one we are using here
# change the model: initialize weights with normal distributions
model = nk.models.Jastrow(kernel_init=nn.initializers.normal())
# Create the an exact sampler over the Hilber space , if it is not too large
sampler = nk.sampler.ExactSampler(hi)
# Construct the variational state using the model and the sampler above.
# n_samples specifies how many samples should be used to compute expectation
# values.
vstate = nk.vqs.MCState(sampler, model, n_samples=2**10)
The VMC driver and the optimization algorithms can stay the same. Only the sampling has changed
optimizer = nk.optimizer.Sgd(learning_rate=0.05)
preconditioner = nk.optimizer.SR(diag_shift=0.1)
# driver for running the simulation
gs = nk.driver.VMC(
H, optimizer, variational_state=vstate, preconditioner=preconditioner
)
We do not call the cb_acc callback here because this exact sampler has no acceptance rate (it is always 1!!)
# Loggers that work together with optimisation drivers are defined in nk.logging.
# RuntimeLog keeps the metrics in memory, JsonLog stores them to a json file which can be read
# as a dict, TensorBoardLog can be used to log to TensorBoard.
log = nk.logging.RuntimeLog()
# One or more logger objects must be passed to the keyword argument `out`.
gs.run(n_iter=300, out=log)
100%|██████████| 300/300 [00:05<00:00, 58.28it/s, Energy=3.1607+0.0000j ± 0.0028 [σ²=0.0117]]
(RuntimeLog():
keys = ['Energy'],)
print(f"Final optimized kernel parameters: {vstate.parameters['kernel']}\n")
jas_energy = vstate.expect(H)
error = abs((jas_energy.mean - eig_vals[0]) / eig_vals[0])
print(f"Optimized energy : {jas_energy}")
print(f"relative error : {error*100:.2f}%")
Final optimized kernel parameters: [[-1.70783517+1.01069444e-02j -0.07502678-6.54106176e-05j
-0.06653237+4.43772603e-05j -0.02631243-1.19484642e-02j
-0.110641 -1.79247926e-03j -0.13704972-6.22070195e-04j]
[-0.08793935-6.39385428e-03j -1.70901641+8.05897637e-03j
-0.06646917-5.48065451e-03j -0.09646871+1.79193912e-02j
-0.01617804+5.92073249e-03j -0.13177261-1.01622964e-02j]
[-0.07401405+4.76853168e-03j -0.06063318+1.79889508e-03j
-1.70474991-1.50494694e-03j -0.12238211+8.51743651e-03j
-0.11521443+1.01223791e-02j -0.04089995+1.69172518e-03j]
[-0.03594193-1.29897463e-02j -0.10875634+1.54751813e-02j
-0.11966952+3.21274355e-03j -1.70394268+2.01133534e-02j
-0.07491248+4.08243238e-04j -0.06654971-6.35513162e-03j]
[-0.08794507-5.28773463e-04j -0.00926488-1.13772738e-02j
-0.11087839-1.46275006e-02j -0.06629862-1.60724854e-02j
-1.71097248+1.11144418e-02j -0.07972108+6.90643908e-03j]
[-0.1249983 +1.75356359e-03j -0.13349868-2.64028565e-03j
-0.04512771-7.72897598e-03j -0.0730808 -7.43176665e-03j
-0.08663991+7.97132918e-03j -1.71506481+3.25330448e-03j]]
Optimized energy : 3.1586+0.0000j ± 0.0030 [σ²=0.0094]
relative error : 0.78%
data_jastrow = log.data
energy_history = data_jastrow["Energy"]["Mean"].real
energy_error_history = data_jastrow["Energy"]["Sigma"]
fig, ax = plt.subplots(figsize=(10, 5))
ax.errorbar(
data_jastrow["Energy"].iters,
energy_history,
yerr=energy_error_history,
label="Jastrow",
)
ax.axhline(
y=eig_vals[0],
xmin=0,
xmax=data_jastrow["Energy"].iters[-1],
linewidth=2,
color="k",
label="Exact",
)
ax.legend()
ax.set_xlabel("Iterations")
ax.set_ylabel("Energy (Re)")
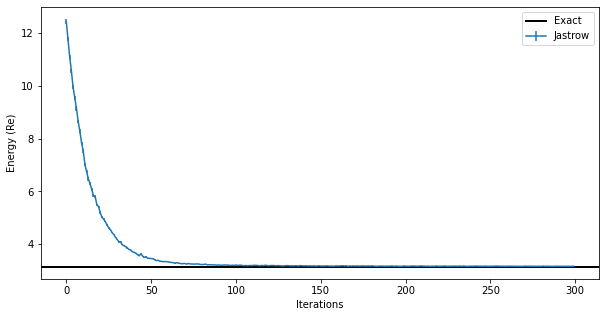
The result obtained with the exact sampler is encouraging because we can see that we have achieved the same accuracy on the ground state energy as before. Even if the Metropolis local sampler does not work well for this ground state, the resulting ground state is still the correct one. The failure in sampling from the computational basis states is due to the fact that, for this system, the ground state is a quantum state that has overlap only on one basis \(|s\rangle\). This happens at very small couplings: remember that the zero-coupling limit is just un-coupled harmonic oscillators.
6. Neural-Network Quantum State#
We now want to use a more sofisticated ansatz, based on a neural network representation of the wave function. At this point, this is quite straightforward, since we can again take advantage of automatic differentiation.
Let us define a simple fully-connected feed-forward network with a ReLu activation function and a sum layer.
class FFN(nn.Module):
# You can define attributes at the module-level
# with a default. This allows you to easily change
# some hyper-parameter without redefining the whole
# flax module. This is the ratio of neurons to input dofs
alpha: int = 1
@nn.compact
def __call__(self, x):
# here we construct the first dense layer using a
# pre-built implementation in flax.
# features is the number of output nodes
dense = nn.Dense(features=self.alpha * x.shape[-1], param_dtype=complex)
# we apply the dense layer to the input
y = dense(x)
# the non-linearity is a simple ReLu
y = nn.relu(y)
# sum the output
return jnp.sum(y, axis=-1)
We will keep using the exact sampler to avoid ergodicity issues
# it is easy here to pass the hyper-parameter value
model = FFN(alpha=1)
# Create the an exact sampler over the Hilber space , if it is not too large
sampler = nk.sampler.ExactSampler(hi)
# create the VMC state
vstate = nk.vqs.MCState(sampler, model, n_samples=2**10)
We then proceed to the optimization as before.
optimizer = nk.optimizer.Sgd(learning_rate=0.05)
preconditioner = nk.optimizer.SR(diag_shift=0.1)
# Notice the use, again of Stochastic Reconfiguration, which considerably improves the optimisation
gs = nk.driver.VMC(
H, optimizer, variational_state=vstate, preconditioner=preconditioner
)
# logging and running : sometimes need to rung longer than 300 to exit a plateaux
log = nk.logging.RuntimeLog()
gs.run(n_iter=300, out=log)
ffn_energy = vstate.expect(H)
error = abs((ffn_energy.mean - eig_vals[0]) / eig_vals[0])
print(f"Optimized energy: {ffn_energy} \nRelative error: {error*100:.2f}%")
Optimized energy: 3.1550+0.0002j ± 0.0027 [σ²=0.0059]
Relative error: 0.67%
100%|██████████| 300/300 [00:05<00:00, 58.55it/s, Energy=3.1573+0.0003j ± 0.0056 [σ²=0.0342]]
And we can compare the results between the two different ansatze. The fully-connected ansatz needs more iterations to converge:
data_FFN = log.data
fig, ax = plt.subplots(figsize=(10, 5))
ax.errorbar(
data_jastrow["Energy"].iters,
data_jastrow["Energy"].Mean.real,
yerr=data_jastrow["Energy"].Sigma,
label="Jastrow",
)
ax.errorbar(
data_FFN["Energy"].iters,
data_FFN["Energy"].Mean.real,
yerr=data_FFN["Energy"].Sigma,
label="FFN",
)
ax.axhline([eig_vals[0]], xmin=0, xmax=300, color="black", label="Exact")
ax.legend()
ax.set_xlabel("Iterations")
ax.set_ylabel("Energy (Re)")
Text(0, 0.5, 'Energy (Re)')
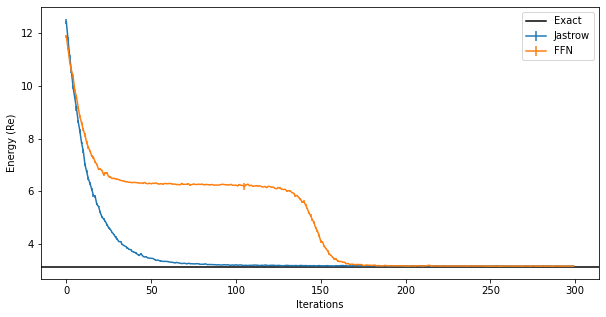
The plateaux in the figure corresponds to a configuration of bosonic levels where all “sites” are in the ground state but one. Getting out of that plateaux is difficult and requires changing the learning rate or the initial set of parameters.
6.1 Increasing the features#
We can try to use more neurons in the dense layer to see if we can get a better result.
This can be done simply by instantiating the FFN model again with a larger alpha.
# it is easy here to pass the hyper-parameter value
model = FFN(alpha=2)
sampler = nk.sampler.ExactSampler(hi)
vstate = nk.vqs.MCState(sampler, model, n_samples=2**10)
optimizer = nk.optimizer.Sgd(learning_rate=0.05)
# Notice the use, again of Stochastic Reconfiguration, which considerably improves the optimisation
gs = nk.driver.VMC(
H,
optimizer,
variational_state=vstate,
preconditioner=nk.optimizer.SR(diag_shift=0.1),
)
gs.run(n_iter=300, out=log)
ffn_energy = vstate.expect(H)
error = abs((ffn_energy.mean - eig_vals[0]) / eig_vals[0])
print(f"Optimized energy: {ffn_energy} \nRelative error: {error*100:.2f}%")
Optimized energy: 3.148e+00-5.581e-04j ± 7.850e-17 [σ²=1.775e-30]
Relative error: 0.45%
100%|██████████| 300/300 [00:05<00:00, 54.37it/s, Energy=3.1492-0.0006j ± 0.0010 [σ²=0.0011]]
This is the best we can do without taking further steps to optimize the learning rate and stochastic gradient descent iterations, which will require more resources.
Clearly we can run for longer, by starting from the current vstate
gs.run(n_iter=300, out=log)
ffn_energy = vstate.expect(H)
error = abs((ffn_energy.mean - eig_vals[0]) / eig_vals[0])
print(f"Optimized energy: {ffn_energy} \nRelative error: {error*100:.2f}%")
Optimized energy: 3.148e+00-3.001e-04j ± 9.583e-21 [σ²=1.175e-38]
Relative error: 0.45%
100%|██████████| 300/300 [00:03<00:00, 82.31it/s, Energy=3.1502-0.0003j ± 0.0014 [σ²=0.0022]]
The very small variance again indicates that the state has a probability distribution peaked on a single state
We can visualize the ground state using vstate.to_array() to expand the wave function on the computational basis of states
fig, ax = plt.subplots(figsize=(10, 5))
ax.bar(np.arange(0, hi.n_states), np.abs(vstate.to_array()), label="FNNmodel")
ax.set_xlim([0, 49])
ax.set_xlabel("basis coordinate")
ax.set_ylabel(r"$\mid \psi \mid$")
ax.legend(loc=0)
<matplotlib.legend.Legend at 0x2af31cac0>

Note: sometimes the FNN ansatz gets stuck on a parameter set that represent the state where only the one “site” is not in the \(|0\rangle\) state, in particular if a non-exact sampler (e.g. Metropolis) is used.
model = FFN(alpha=1)
vstate = nk.vqs.MCState(nk.sampler.MetropolisLocal(hi), model, n_samples=2**10)
optimizer = nk.optimizer.Sgd(learning_rate=0.05)
# Notice the use, again of Stochastic Reconfiguration, which considerably improves the optimisation
gs = nk.driver.VMC(
H,
optimizer,
variational_state=vstate,
preconditioner=nk.optimizer.SR(diag_shift=0.1),
)
gs.run(n_iter=300, out=log)
ffn_energy = vstate.expect(H)
error = abs((ffn_energy.mean - eig_vals[0]) / eig_vals[0])
print(f"Optimized energy: {ffn_energy} \nRelative error: {error*100:.2f}%")
Optimized energy: 3.1666-0.0012j ± 0.0058 [σ²=0.0180, R̂=1.1561]
Relative error: 1.04%
100%|██████████| 300/300 [00:05<00:00, 52.97it/s, Energy=3.1578-0.0013j ± 0.0039 [σ²=0.0082, R̂=1.0695]]
fig, ax = plt.subplots(ncols=N, figsize=(30, 8))
for i, axi in enumerate(ax):
axi.plot(vstate.samples[:, :, i].flatten(), ".", label=f"site {i}")
axi.set_ylim(-0.1, Lambda - 0.9)
axi.legend()

print(f"Number of parameters (FFN(alpha=1)): {vstate.n_parameters}")
Number of parameters (FFN(alpha=1)): 42
7. Autoregressive models#
In this paper, an autoregressive flow model was used to parametrize the modulus of the wave function, while a fully-connected layer was used for the phase. Although the paper consider matrices in the coordinate basis, we here continue using the discrete Fock basis.
Autoregressive models are included in NetKet, together with direct samplers for their conditional distributions (see this link for a fully-connected autoregressive model)
model = nk.models.ARNNDense(hilbert=hi, layers=3, features=10)
# the autoregressive model has an exact sampler because of the conditional prob
sampler = nk.sampler.ARDirectSampler(hi)
# With direct sampling, we don't need many samples in each step to form a
# Markov chain, and we don't need to discard samples
vstate = nk.vqs.MCState(sampler, model, n_samples=2**6)
print(f"Number of parameters (ARNNDense): {vstate.n_parameters}")
Number of parameters (ARNNDense): 5544
This model has a much larger number of parameters compared to the fully-connected ansatz we used above.
Then we can call our driver as before
optimizer = nk.optimizer.Sgd(learning_rate=0.1)
preconditioner = nk.optimizer.SR(diag_shift=0.1)
# Notice the use, again of Stochastic Reconfiguration, which considerably improves the optimisation
gs = nk.driver.VMC(
H, optimizer, variational_state=vstate, preconditioner=preconditioner
)
# logging and running
log = nk.logging.RuntimeLog()
gs.run(n_iter=1000, out=log)
arnn_energy = vstate.expect(H)
error = abs((arnn_energy.mean - eig_vals[0]) / eig_vals[0])
print(f"Optimized energy: {arnn_energy} \nRelative error: {error*100:.2f}%")
Optimized energy: 3.150e+00 ± nan [σ²=0.000e+00]
Relative error: 0.51%
100%|██████████| 1000/1000 [00:13<00:00, 75.88it/s, Energy=3.150e+00 ± nan [σ²=0.000e+00]]
8. Measuring Other Properties#
Once the model has been optimized, we can measure other observables that are not the energy. For example, we could measure the generators of the gauge transformations.
We could also use a larger number of samples to have a sufficiently low error bar on their measurement, by changing vstate.n_samples on the fly.
The Casimir operator for the gauge group is defined using a combination of \(\hat{a}^\dagger_I\) and \(\hat{a}_I\) for each boson. We are assuming that sites 0, 1, and 2 are for the 3 gauge dof of one matrix and site 3, 4, and 5 are for the other matrix. Given this assignment we can write
using the matrices on the 6 bosonic sites defined at the beginning. Overall, the Gauge Casimir operator is
g_list = [0] * 3
g_list[0] = 1j * (
create(hi, 1) @ destroy(hi, 2)
- create(hi, 2) @ destroy(hi, 1)
+ create(hi, 4) @ destroy(hi, 5)
- create(hi, 5) @ destroy(hi, 4)
)
g_list[1] = 1j * (
create(hi, 2) @ destroy(hi, 0)
- create(hi, 0) @ destroy(hi, 2)
+ create(hi, 5) @ destroy(hi, 3)
- create(hi, 3) @ destroy(hi, 5)
)
g_list[2] = 1j * (
create(hi, 0) @ destroy(hi, 1)
- create(hi, 1) @ destroy(hi, 0)
+ create(hi, 3) @ destroy(hi, 4)
- create(hi, 4) @ destroy(hi, 3)
)
G = sum([g * g for g in g_list])
We can sample 1024 times to get a more accurate result. We expect to find zero if the ground state is gauge invariant
vstate.n_samples = 2**10
vstate.expect(G)
0.000e+00+0.000e+00j ± nan [σ²=0.000e+00]