Ground-State: Bosons in a 3D Harmonic trap#
Gabriel Pescia (EPFL-CQSL)
13 September, 2023
In this Tutorial we will explore the capabilities of NetKet to study the ground-state of bosonic many-body quantum systems in continuous space. As a first step we will consider an easy problem of non-interacting harmonic oscillators in free, three dimensional space, to introduce and explain the moving parts needed to perform a VMC optimization. Subsequently a more challenging example of interacting bosons in one dimensions with periodic boundary conditions will be studied.
Specifically, we will study the following two Hamiltonians:
and
,where the first term represents the kinetic energy contribution of particles of mass \(m\), and the second term is the potential (interaction) energy ( \( \mathbf{r}_{ij} = \mathbf{x}_i-\mathbf{x}_j \) ). In the following we set \(m = \omega = \hbar = \frac{\epsilon}{2} =1\).
Note
If you are executing this notebook on Colab, you will need to install NetKet. You can do so by uncommenting and running the following cell.
Keep in mind that this notebook was designed for NetKet version 3.9.1, which requires Python >=3.8. If you do not have access to a recent version of Python we strongly recomend to run this notebook on google Colab.
# %pip install --upgrade netket>=3.9.1
Please verify that you are running on the correct version of NetKet. If the installation installed an older version of NetKet, it might be because your Python version is too old. In that case, you will need to upgrade python or use Colab.
It might also be that in the future NetKet changes. This notebook was authored for the following version of NetKet:
import platform
import netket as nk
print("Python version (requires >=3.9)", platform.python_version())
print("NetKet version (requires >=3.9.1)", nk.__version__)
Python version (requires >=3.9) 3.13.2
NetKet version (requires >=3.9.1) 3.17.2.dev7+g24d80ac4.d20250527
1. Defining The Hilbert Space and Sampler#
The first ingredient in defining our problem in NetKet, consists of defining the Hilbert Space to study. For continuous space systems, the Hilbert space takes information about the number of particles, the size of the system and the type of boundary conditions: open or periodic. The dimensionality of space is inferred from the size of the system. The species of particles (bosonic or fermionic) is not relevant for the Hilbert space but only in defining the variational Ansatz (symmetric or antisymmetric). In the following the Hilbert space for \(N=10\) particles in open (infinite) space is defined.
import jax.numpy as jnp
N = 10
# 10 particles in 3D space without periodic boundary conditions.
# The length of the L-tuple indicates the spatial dimension of space.
geo = nk.experimental.geometry.FreeSpace(d=3)
hi = nk.experimental.hilbert.Particle(N=N, geometry=geo)
We can now generate random configurations in the Hilbert space, we just defined. For the above specifications the random state will consists of a vector of \(N*d = 10*3\) numbers (\(d\) number of spatial dimensions), representing the 10 3D positions of the particles under consideration.
import jax
states = hi.random_state(jax.random.key(0), 1)
# You can always reshape those configurations to NxD matrix
states.reshape(N, 3)
Array([[-0.20584214, -0.78476578, 1.81608667],
[ 0.18784401, 0.08086788, -0.37211079],
[ 1.19016372, 0.33864229, 0.08482584],
[-0.87181784, 1.05451609, -1.5594979 ],
[ 0.36753958, 2.51635215, 0.25856516],
[-0.28371043, -0.53389115, 0.36794769],
[-0.1959642 , 1.50407679, 0.05904905],
[ 0.1415813 , 0.18851565, 0.04672933],
[-1.4134907 , -0.19496338, 1.11302457],
[-2.22703843, -0.56259627, 0.30136156]], dtype=float64)
Of course we are not particularily interested in random states of our Hilbert space, but we rather want to be able to sample from a probability distribution, defined in the Hilbert space. To do this, NetKet provides the Metropolis-Hasting sampler. This sampler uses an initial state in the Hilbert space (e.g. a random state) and produces a new state according to a transtition rule. The new state is accepted (e.g. becomes the initial state for another update according to the transition rule) if its probability is high enough (the probability of the state is determined by the variational Ansatz, see later). While you can write your own transition rule, NetKet already implements a common transition rule, that often is sufficient to run a VMC optimization.
For distributed computing across multiple devices, NetKet uses JAX’s automatic sharding capabilities. This allows for efficient parallelization of sampling and computation without requiring manual configuration.
The transition rule is given by adding normally distributed noise to the initial state:
where \( \mathbf{\delta}_i \sim \mathcal{N}(0,\sigma^2) \) and \( \sigma \) is chosen by the user, dependent on the system under consideration. To decorrelate samples, the sampler provides functionality to insert more substeps of the above rule (e.g. add Gaussian noise multiple times). You can also specify how many parallel chains of the above rule you want to run. In the following, we initialize the sampler, with \( \sigma=0.1 \), 16 parallel chains, with 32 substeps of the transition rule.
sa = nk.sampler.MetropolisGaussian(hi, sigma=0.1, n_chains=16, sweep_size=32)
2. Defining The Hamiltonian#
Now that the Hilbert space is defined, we also have to specify the Hamiltonian the particles are subject to. As written above we will start with a simple example of non-interacting particles, confined by a harmonic potential e.g. a collection of harmonic oscillators. A Hamiltonian in continuous space usually consists of two parts: kinetic and potential energy. The form of the kinetic energy is always the same and only depends on the mass of the particles. NetKet provides a full implementation of the the kinetic energy, which is simply the trace of the (weighted) Hessian taken with respect to all the input variables of the variational state.
In the following we initialize the kinetic energy operator for particles of masses \( m=1 \) (one could also provide a tuple of different masses for each particle).
ekin = nk.operator.KineticEnergy(hi, mass=1.0)
The potential energy part changes when changing from one system to another and therefore needs to be implemented from scratch. In NetKet this amounts to writing a function that takes a single sample \( \mathbf{X} \) and outputs a single number representing the potential energy of the given configuration. For a harmonic confinement we have:
or in code:
def v(x):
return 0.5 * jnp.linalg.norm(x) ** 2
To use this function as an operator, NetKet provides a potential energy operator:
pot = nk.operator.PotentialEnergy(hi, v)
All left to do to define the complete Hamiltonian, is combine the kinetic and potential energy operators into a single operator object:
ha = ekin + pot
3. Exact Ansatz#
The most important thing for every VMC simulation is the variational Ansatz to the problem. If the Ansatz is capable of representing the true ground-state, the VMC results will be significantly better compared to a poorly chosen Ansatz that cannot represent the ground-state. For the case of non-interacting harmonic oscillators we know exactly what the many-body ground-state looks like:
with associated probability distribution \(P(\mathbf{X}) = \prod_i \exp\left[-|\mathbf{x}_i|^2\right]\). To provide some first experience with NetKet in continuous space, we first choose a variational parameterization that can exactly represent the above state:
which is the ground-state for \( \Sigma^{-1} = \mathbb{I} \).
The Model can be defined using one of the several functional jax frameworks such as Jax/Stax, Flax or Haiku. NetKet includes several pre-built models and layers built with Flax, including the above multivariate Gaussian Ansatz. For completeness the model definition is copied below (to make sure that \( \Sigma^{-1} \) is a proper covariance matrix (positive definite), we parameterize it as \( \Sigma^{-1} = T T^T \)):
import flax.linen as nn
from flax.linen.dtypes import promote_dtype
from flax.linen.initializers import normal
from netket.utils.types import DType, Array, NNInitFunc
class Gaussian(nn.Module):
r"""
Multivariate Gaussian function with mean 0 and parametrised covariance matrix
:math:`\Sigma_{ij}`.
The wavefunction is given by the formula: :math:`\Psi(x) = \exp(\sum_{ij} x_i \Sigma_{ij} x_j)`.
The (positive definite) :math:`\Sigma_{ij} = AA^T` matrix is stored as
non-positive definite matrix A.
"""
param_dtype: DType = jnp.float64
"""The dtype of the weights."""
kernel_init: NNInitFunc = normal(stddev=1.0)
"""Initializer for the weights."""
@nn.compact
def __call__(self, x_in: Array):
nv = x_in.shape[-1]
kernel = self.param("kernel", self.kernel_init, (nv, nv), self.param_dtype)
kernel = jnp.dot(kernel.T, kernel)
kernel, x_in = promote_dtype(kernel, x_in, dtype=None)
y = -0.5 * jnp.einsum("...i,ij,...j", x_in, kernel, x_in)
return y
The model above gives instructions on how to initialize the variational parameters and evaluate the model. To use it in the context of the VMC optimization, NetKet provides the Monte-Carlo-sampled Variational State netket.vqs.MCState, which requires a sampler and a model from which to sample from. We also have to provide the number of samples from which expectation values of operators are computed, at each iteration of the VMC optimization.
In the following we construct the variational state from the multivariate Gaussian Ansatz above, using the Gaussian sampler to sample from it and we choose a total of 10000 samples per iteration.
# Create an instance of the model.
# Notice that this does not create the parameters.
Gauss = Gaussian()
# Construct the variational state using the model and the sampler above.
# n_samples specifies how many samples should be used to compute expectation
# values.
vstate = nk.vqs.MCState(sa, Gauss, n_samples=10**4, n_discard_per_chain=100)
You can play around with the variational state: for example, you can compute expectation values yourself or inspect it’s parameters
import matplotlib.pyplot as plt
# you can inspect the parameters which form a N*dxN*d matrix
plt.imshow(vstate.parameters["kernel"])
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x127e8c980>
# Expectation value: notice that it also provides an error estimate.
E = vstate.expect(ha)
print(E)
243.7 ± 1.9 [σ²=7275.1, R̂=1.0092]
# the energy (expectation value) is a structure with a lot of fields:
print("Mean :", E.mean)
print("Error :", E.error_of_mean)
print("Variance :", E.variance)
print("Convergence indicator :", E.R_hat)
print("Correlation time :", E.tau_corr)
Mean : 243.67295169464077
Error : 1.94587920493069
Variance : 7275.126948395135
Convergence indicator : 1.0092192481951645
Correlation time : 2.102322892122845
4. Variational Monte Carlo#
We will now try to optimise the covariance matrix \( \Sigma^{-1} \) in order to best approximate the ground state of the hamiltonian, which has a ground-state energy of \( \frac{1}{2}N*d=15 \).
At first, we’ll try to do this by ourself by writing the training loop, but then we’ll switch to using a pre-made solution provided by netket for simplicity.
4. Use NetKet’s optimisation driver#
The optimisation (or training) loop must do a very simple thing: at every iteration it must compute the energy and it’s gradient, then multiply the gradient by a certain learning rate and lastly it must update the parameters with this rescaled gradient.
We use NetKet’s default VMC optimisation loop for that
# First we reset the parameters to run the optimisation again
vstate.init_parameters(normal(stddev=1.0))
# Then we create an optimiser from the standard library.
# You can also use optax.
optimizer = nk.optimizer.Sgd(learning_rate=0.05)
# build the optimisation driver
gs = nk.driver.VMC(ha, optimizer, variational_state=vstate)
# run the driver for 150 iterations. This will display a progress bar
# by default.
log = nk.logging.RuntimeLog()
gs.run(n_iter=150, out=log)
energy = vstate.expect(ha)
error = jnp.abs(energy.mean - 15.0) / 15.0
print("Optimized energy and relative error: ", energy, error)
Optimized energy and relative error: 14.999987 ± 0.000031 [σ²=0.000002, R̂=1.0079] 8.498904531251128e-07
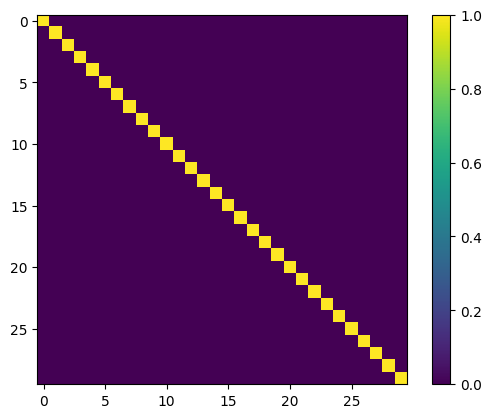
# we can again inspect the parameter:
kernel = vstate.parameters["kernel"]
plt.imshow(jnp.dot(kernel.T, kernel))
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x13382d450>
5. Neural-Network Quantum State#
Rarely do we know the functional form of the ground state wave-function. We therefore have to resort to highly flexible variational Ansaetze, capable of representing many different many-body states. We can for example use neural networks as universal function approximators. In the following, we use a neural network architecture called “DeepSets” to solve the more interesting case of bosons interacting via a repulsive Gaussian interaction:
We study the bulk of the system by confining it into a box of length \(L\) with periodic boundary conditions. In this extended system we define the particle density as \( D = N/L^d \) and we study the case \( D=1 \) for \( N=20 \) particles in \( d=1 \) dimensions with \( \epsilon = 2 \). To account for the periodicity we use the minimum image convention when evaluating the potential energy of the system. For more information see:
The DeepSets architecture we use is defined as:
where the functions \( \phi \) and \( \rho \) are parameterized by simple feed-forward neural network with a GeLu activation function with one hidden layer. To account for periodicity we choose as input \( \mathbf{y}_{ij} = (\sin(\frac{2\pi}{L} \mathbf{r}_{ij}), \cos(\frac{2\pi}{L} \mathbf{r}_{ij})) \).
See PRR 4, 023138 (2022) for more information.
First we define the Hilbert space, sampler and hamiltonian:
def minimum_distance(x, N, sdim):
"""Computes distances between particles using minimum image convention"""
x = x.reshape(-1, N, sdim)
idx = jnp.triu_indices(N, 1)
distances = (-x[..., None, :, :] + x[..., :, None, :])[..., idx[0], idx[1], :]
# minimum image convention
distances = jnp.remainder(distances + L / 2.0, L) - L / 2.0
return jnp.linalg.norm(distances, axis=-1)
def potential(x, N, epsilon, sdim):
dis = minimum_distance(x, N, sdim)
return epsilon * jnp.sum(jnp.exp(-((dis) ** 2)))
N = 20
D = 1.0
dim = 1
epsilon = 2.0
L = (N / D) ** (1 / dim)
geo = nk.experimental.geometry.Cell(d=1, L=(L,), pbc=True)
hilb = nk.experimental.hilbert.Particle(N=N, geometry=geo)
sa = nk.sampler.MetropolisGaussian(hilbert=hilb, sigma=0.4, n_chains=16, sweep_size=10)
ekin = nk.operator.KineticEnergy(hilb, mass=1.0)
pot = nk.operator.PotentialEnergy(hilb, lambda x: potential(x, N, epsilon, dim))
ha = ekin + pot
class DS(nn.Module):
# You can define attributes at the module-level
# with a default. This allows you to easily change
# some hyper-parameter without redefining the whole
# flax module.
L: float
N: int
sdim: int
hidden_units: int = 8
@nn.compact
def __call__(self, x):
x = x.reshape(-1, self.N, self.sdim)
xij = x[..., None, :] - x[..., None, :, :]
yij = jnp.concatenate(
(jnp.sin(2 * jnp.pi / self.L * xij), jnp.cos(2 * jnp.pi / self.L * xij)),
axis=-1,
)
### PHI
# here we construct the first dense layer using a
# pre-built implementation in flax.
# features is the number of output nodes
y = nn.Dense(features=self.hidden_units)(yij)
# the non-linearity is a simple GeLu
y = nn.gelu(y)
# we apply the dense layer to the input
y = nn.Dense(features=self.hidden_units)(y)
# we sum over i,j
y = jnp.sum(y, axis=(-3, -2))
### RHO
# the function rho has a single output
y = nn.Dense(features=self.hidden_units)(y)
y = nn.gelu(y)
y = nn.Dense(features=1)(y)
return y.squeeze()
model = DS(L=L, N=N, sdim=dim)
# choose number of samples that is divided by the number of chains
vstate = nk.vqs.MCState(sa, model, n_samples=1008, n_discard_per_chain=16)
We then proceed to the optimization as before.
optimizer = nk.optimizer.Sgd(learning_rate=0.02)
# Notice the use, again of Stochastic Reconfiguration, which considerably improves the optimisation
gs = nk.driver.VMC(
ha,
optimizer,
variational_state=vstate,
preconditioner=nk.optimizer.SR(diag_shift=0.05),
)
# Store the energy along the simulation in a RuntimeLogger, which is kept in memory.
# You could also use a JsonLog to save it to a file.
log = nk.logging.RuntimeLog()
gs.run(n_iter=200, out=log)
ds_energy = vstate.expect(ha)
error = abs((ds_energy.mean - 24.742) / 24.742)
print("Optimized energy and relative error: ", ds_energy, error)
Optimized energy and relative error: 24.7591 ± 0.0083 [σ²=0.0691, R̂=1.0064] 0.0006925251586689619
6. Measuring Other Properties#
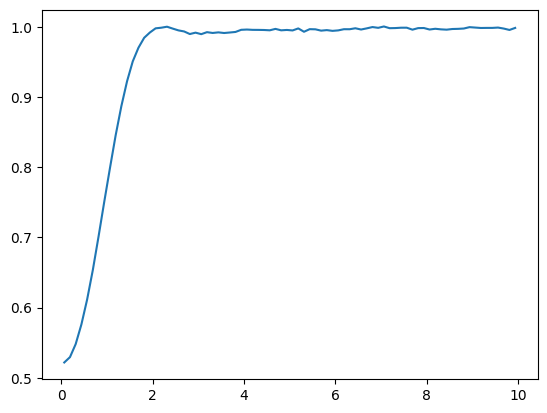
Once the model has been optimized, we can of start to measure other observables than the energy as well. An interesting quantity could for example be the radial distribution function, which is related to the structure factor measured in scattering experiments. It is defined as:
where \( \langle \cdot \rangle \) denotes the expectation value w.r.t. the probability distribution defined by the optimized wave-function. The constant \(C\) is chosen such that \(\int \mathrm{d}r g(r) = N*(N-1)\).
To evaluate the above expression we need samples from the optimized wave-function:
samples = vstate.sample(chain_length=3 * 10**4)
Then we compute the above observable by computing the distances \(r_{ij}\) and computing a histogram of the result (the finer the histogram the closer we approximate the delta-distribution).
import numpy as np
import jax
def gr(samples, n_particles, sdim, L, bins=80):
dists = minimum_distance(samples, n_particles, sdim)
hist, bin_edges = np.histogram(dists.flatten(), bins=bins, range=(0, L / 2))
delta_r = bin_edges[1] - bin_edges[0]
centers = (bin_edges[1:] + bin_edges[:-1]) / 2
gC = hist / (dists.shape[0] * n_particles)
def get_jacobian():
if sdim == 1:
return np.ones_like(centers)
elif sdim == 2:
return 2 * np.pi * centers
elif sdim == 3:
return 4 * np.pi * centers**2
else:
raise NotImplementedError(
f"Jacobian factor not yet implemented for sdim={sdim}"
)
def get_volume():
return L**sdim
def get_density():
return n_particles / get_volume()
gU = get_jacobian() * delta_r * get_density()
return centers, gC / gU
c, g = gr(samples, n_particles=N, sdim=dim, L=L)
plt.plot(c, g)